


With the incorporation of enormous language fashions (LLMs) in nearly all fields of know-how, processing giant datasets for language fashions poses challenges by way of scalability and effectivity. The core concern is the formidable job of managing, cleansing, and organizing large datasets which are essential for coaching refined LLMs. Addressing this problem requires an answer that’s scalable, versatile, and accessible to a variety of customers, from particular person researchers to giant groups engaged on the state-of-the-art facet of AI growth.
Current analysis emphasizes the importance of distributed processing and knowledge high quality management for enhancing LLMs. Using frameworks like Slurm and Spark permits environment friendly massive knowledge administration, whereas knowledge high quality enhancements by means of deduplication, decontamination, and sentence size changes refine coaching datasets. The ETL (Extract, Remodel, Load) course of can be important in aggregating and processing knowledge from various sources. Regardless of their effectiveness, these strategies and frameworks should present a unified, customizable resolution for all LLM knowledge processing wants.
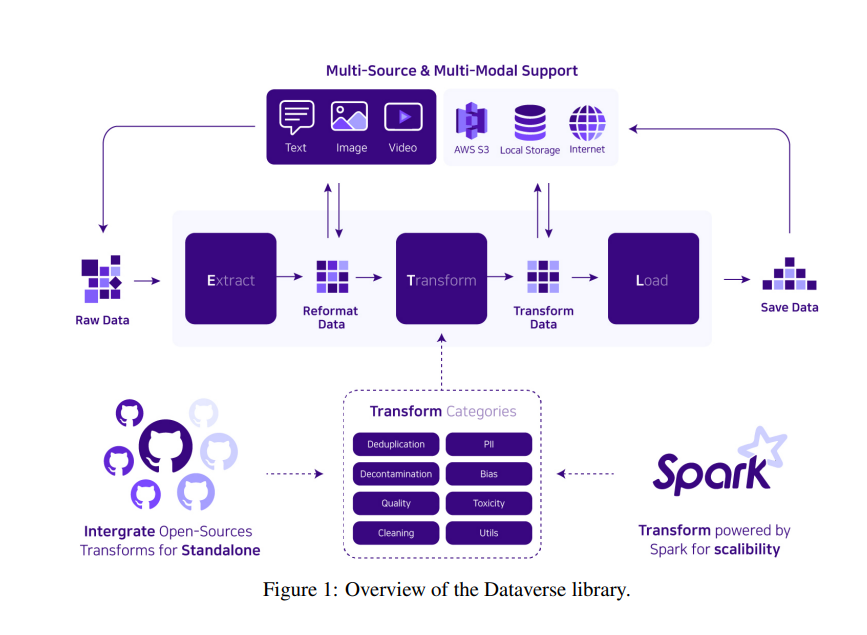
Researchers from Upstage AI have launched Dataverse, an modern ETL pipeline crafted to boost knowledge processing for LLMs. Dataverse stands out by providing a unified, customizable framework that simplifies the development and modification of ETL pipelines, aiming to streamline knowledge administration and enhance the event means of LLMs.
Dataverse’s methodology facilities on a block-based interface for customizable ETL pipelines, using Apache Spark for distributed processing and AWS for cloud-based scalability. It incorporates a decorator sample for simple integration of customized knowledge operations. The system is meticulously designed for prime flexibility in knowledge processing duties, together with deduplication, bias mitigation, and toxicity elimination, with out specifying using explicit datasets within the paper. By enabling multi-source knowledge ingestion—from native storage to cloud platforms and internet scraping—Dataverse reassures you of its adaptability, facilitating environment friendly knowledge preparation for LLM growth and streamlining the workflow from knowledge assortment to processing.
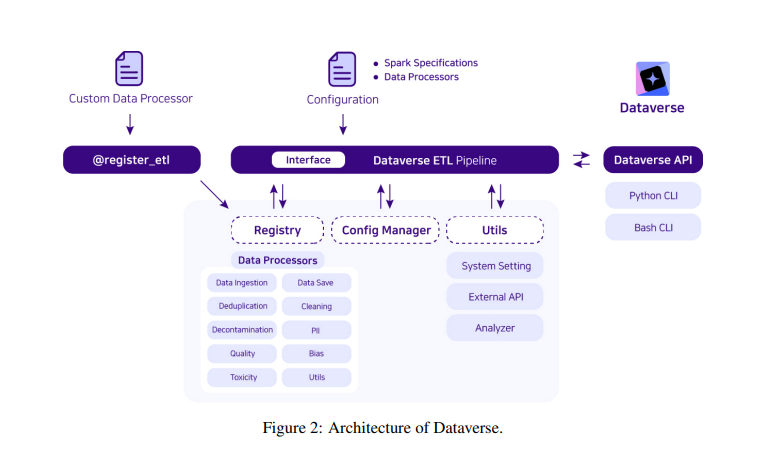
To conclude, the analysis carried out by Upstage AI introduces Dataverse, an open-source ETL pipeline designed to considerably enhance the information processing for LLMs. By incorporating a block-based interface, Apache Spark, and AWS integration, Dataverse presents a scalable and customizable resolution for managing giant datasets. The device’s emphasis on simplifying the ETL course of and its potential to streamline the event of LLMs highlights its significance in advancing AI analysis. It evokes intrigue about its potential impression on knowledge processing. Regardless of missing quantitative outcomes, Dataverse’s modern strategy marks a major contribution to the sector of information processing, sparking curiosity about its future purposes.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to affix our 39k+ ML SubReddit
![]()
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.