


The sector of pure language processing has been remodeled by the arrival of Massive Language Fashions (LLMs), which give a variety of capabilities, from easy textual content technology to classy problem-solving and conversational AI. Because of their refined architectures and immense computational necessities, these fashions have change into indispensable in cloud-based AI functions. Nonetheless, deploying these fashions in cloud providers presents distinctive challenges, notably in dealing with auto-regressive textual content technology’s dynamic and iterative nature, particularly for duties involving lengthy contexts. Conventional cloud-based LLM providers typically want extra environment friendly useful resource administration, resulting in efficiency degradation and useful resource wastage.
The first concern lies within the dynamic nature of LLMs, the place every newly generated token is appended to the present textual content corpus, forming the enter for recalibration throughout the LLM. This course of requires substantial and fluctuating reminiscence and computational sources, presenting vital challenges in designing environment friendly cloud-based LLM service techniques. Present techniques, akin to PagedAttention, have tried to handle this by facilitating information trade between GPU and CPU reminiscence. Nonetheless, these strategies are restricted by their scope, as they’re restricted to the reminiscence inside a single node and thus can not effectively deal with extraordinarily lengthy context lengths.
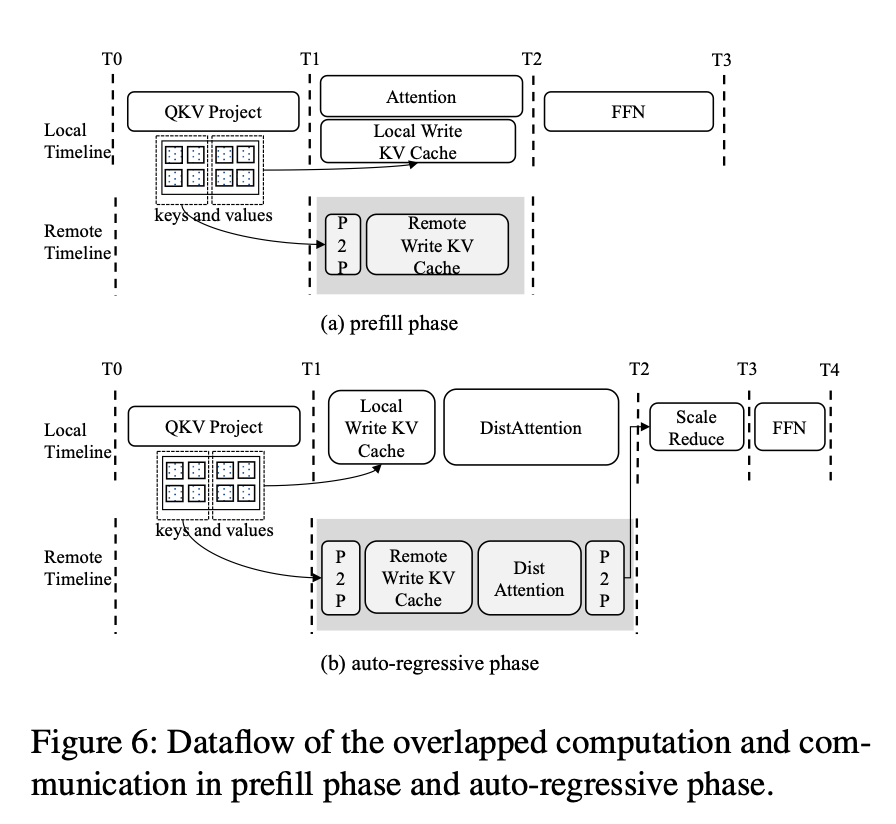
In response, the Ali Baba Group and the Shanghai Jiao Tong College researchers introduce an revolutionary distributed consideration algorithm, DistAttention, which segments the Key-Worth (KV) Cache into smaller, manageable items, enabling distributed processing and storage of the eye module. This segmentation effectively handles exceptionally lengthy context lengths, avoiding the efficiency fluctuations sometimes related to information swapping or stay migration processes. The paper proposes DistKV-LLM, a distributed LLM serving system that dynamically manages KV Cache and orchestrates all accessible GPU and CPU reminiscences throughout the information heart.
DistAttention breaks down conventional consideration computation into smaller items referred to as macro-attentions (MAs) and their corresponding KV Caches (rBlocks). This method allows impartial mannequin parallelism methods and reminiscence administration for consideration layers versus different layers throughout the Transformer block. DistKV-LLM excels in managing these KV Caches, coordinating reminiscence utilization effectively amongst distributed GPUs and CPUs all through the information heart. When an LLM service occasion faces a reminiscence deficit resulting from KV Cache enlargement, DistKV-LLM proactively borrows supplementary reminiscence from much less burdened situations. This intricate protocol facilitates environment friendly, scalable, and coherent interactions amongst quite a few LLM service situations working within the cloud, enhancing the general efficiency and reliability of the LLM service.
The system exhibited vital enhancements in end-to-end throughput, reaching 1.03-2.4 occasions higher efficiency than current state-of-the-art LLM service techniques. It additionally supported context lengths as much as 219 occasions longer than present techniques, as evidenced by in depth testing throughout 18 datasets with context lengths as much as 1,900K. These checks have been performed in a cloud atmosphere with 32 NVIDIA A100 GPUs in configurations from 2 to 32 situations. The improved efficiency is attributed to DistKV-LLM’s means to orchestrate reminiscence sources throughout the information heart successfully, guaranteeing high-performance LLM service adaptable to a broad vary of context lengths.
This analysis provides a groundbreaking answer to the challenges confronted by LLM providers in cloud environments, particularly for long-context duties. The DistAttention and DistKV-LLM techniques symbolize a big leap ahead in addressing the vital problems with dynamic useful resource allocation and environment friendly reminiscence administration. This revolutionary method paves the way in which for extra sturdy and scalable LLM cloud providers, setting a brand new normal for deploying giant language fashions in cloud-based functions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible functions. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.