


Giant Language Fashions (LLMs) have change into more and more pivotal within the burgeoning subject of synthetic intelligence, particularly in information administration. These fashions, that are based mostly on superior machine studying algorithms, have the potential to streamline and improve information processing duties considerably. Nevertheless, integrating LLMs into repetitive information era pipelines is difficult, primarily resulting from their unpredictable nature and the potential for important output errors.
Operationalizing LLMs for large-scale information era duties is fraught with complexities. As an illustration, in capabilities like producing customized content material based mostly on consumer information, LLMs would possibly carry out extremely in a number of circumstances but additionally danger inflicting incorrect or inappropriate content material. This inconsistency can result in important points, notably when LLM outputs are utilized in delicate or important purposes.
Managing LLMs inside information pipelines has relied closely on guide interventions and fundamental validation strategies. Builders face substantial challenges in predicting all potential failure modes of LLMs. This issue results in an over-reliance on fundamental frameworks incorporating rudimentary assertions to filter out faulty information. These assertions, whereas helpful, should be extra complete to catch all sorts of errors, leaving gaps within the information validation course of.
The introduction of Spade, a technique for synthesizing assertions in LLM pipelines by researchers from UC Berkeley, HKUST, LangChain, and Columbia College, considerably advances this space. Spade addresses the core challenges in LLM reliability and accuracy by innovatively synthesizing and filtering assertions, guaranteeing high-quality information era in numerous purposes. It capabilities by analyzing the variations between consecutive variations of LLM prompts, which frequently point out particular failure modes of the LLMs. Based mostly on this evaluation, spade synthesizes Python capabilities as candidate assertions. These capabilities are then meticulously filtered to make sure minimal redundancy and most accuracy, addressing the complexities of LLM-generated information.
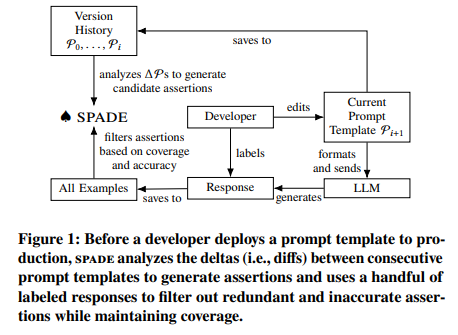
Spade’s methodology entails producing candidate assertions based mostly on immediate deltas – the variations between consecutive immediate variations. These deltas typically point out particular failure modes that LLMs would possibly encounter. For instance, an adjustment in a immediate to keep away from complicated language would possibly necessitate an assertion to examine the response’s complexity. As soon as these candidate assertions are generated, they bear a rigorous filtering course of. This course of goals to cut back redundancy, which frequently stems from repeated refinements to comparable parts of a immediate, and to reinforce accuracy, notably in assertions involving complicated LLM calls.
In sensible purposes, throughout numerous LLM pipelines, it has considerably diminished the variety of mandatory assertions and decreased the speed of false failures. That is evident in its capacity to cut back the variety of assertions by 14% and reduce false failures by 21% in comparison with less complicated baseline strategies. These outcomes spotlight Spade’s functionality to reinforce the reliability and accuracy of LLM outputs in information era duties, making it a useful instrument in information administration.

In abstract, the next factors can introduced on the analysis performed:
- Spade represents a breakthrough in managing LLMs in information pipelines, addressing the unpredictability and error potential in LLM outputs.
- It generates and filters assertions based mostly on immediate deltas, guaranteeing minimal redundancy and most accuracy.
- The instrument has considerably diminished the variety of mandatory assertions and the speed of false failures in numerous LLM pipelines.
- Its introduction is a testomony to the continued developments in AI, notably in enhancing the effectivity and reliability of knowledge era and processing duties.
This complete overview of Spade underscores its significance within the evolving panorama of AI and information administration. Spade ensures high-quality information era by addressing the elemental challenges related to LLMs. It simplifies the operational complexities related to these fashions, paving the best way for his or her simpler and widespread use.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our Telegram Channel
![]()
Hiya, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about expertise and need to create new merchandise that make a distinction.