



Deep studying has lately made super progress in a variety of issues and purposes, however fashions typically fail unpredictably when deployed in unseen domains or distributions. Supply-free area adaptation (SFDA) is an space of analysis that goals to design strategies for adapting a pre-trained mannequin (educated on a “supply area”) to a brand new “goal area”, utilizing solely unlabeled knowledge from the latter.
Designing adaptation strategies for deep fashions is a crucial space of analysis. Whereas the growing scale of fashions and coaching datasets has been a key ingredient to their success, a damaging consequence of this pattern is that coaching such fashions is more and more computationally costly, in some circumstances making massive mannequin coaching much less accessible and unnecessarily growing the carbon footprint. One avenue to mitigate this subject is thru designing methods that may leverage and reuse already educated fashions for tackling new duties or generalizing to new domains. Certainly, adapting fashions to new duties is extensively studied underneath the umbrella of switch studying.
SFDA is a very sensible space of this analysis as a result of a number of real-world purposes the place adaptation is desired endure from the unavailability of labeled examples from the goal area. The truth is, SFDA is having fun with growing consideration [1, 2, 3, 4]. Nevertheless, albeit motivated by bold objectives, most SFDA analysis is grounded in a really slender framework, contemplating easy distribution shifts in picture classification duties.
In a big departure from that pattern, we flip our consideration to the sector of bioacoustics, the place naturally-occurring distribution shifts are ubiquitous, typically characterised by inadequate goal labeled knowledge, and signify an impediment for practitioners. Learning SFDA on this utility can, due to this fact, not solely inform the tutorial neighborhood in regards to the generalizability of present strategies and determine open analysis instructions, however may also instantly profit practitioners within the area and support in addressing one of many greatest challenges of our century: biodiversity preservation.
On this submit, we announce “In Seek for a Generalizable Technique for Supply-Free Area Adaptation”, showing at ICML 2023. We present that state-of-the-art SFDA strategies can underperform and even collapse when confronted with lifelike distribution shifts in bioacoustics. Moreover, present strategies carry out otherwise relative to one another than noticed in imaginative and prescient benchmarks, and surprisingly, typically carry out worse than no adaptation in any respect. We additionally suggest NOTELA, a brand new easy technique that outperforms present strategies on these shifts whereas exhibiting robust efficiency on a spread of imaginative and prescient datasets. Total, we conclude that evaluating SFDA strategies (solely) on the commonly-used datasets and distribution shifts leaves us with a myopic view of their relative efficiency and generalizability. To dwell as much as their promise, SFDA strategies have to be examined on a wider vary of distribution shifts, and we advocate for contemplating naturally-occurring ones that may profit high-impact purposes.
Distribution shifts in bioacoustics
Naturally-occurring distribution shifts are ubiquitous in bioacoustics. The biggest labeled dataset for chook songs is Xeno-Canto (XC), a group of user-contributed recordings of untamed birds from internationally. Recordings in XC are “focal”: they aim a person captured in pure circumstances, the place the track of the recognized chook is on the foreground. For steady monitoring and monitoring functions, although, practitioners are sometimes extra desirous about figuring out birds in passive recordings (“soundscapes”), obtained by omnidirectional microphones. This can be a well-documented drawback that latest work exhibits could be very difficult. Impressed by this lifelike utility, we research SFDA in bioacoustics utilizing a chook species classifier that was pre-trained on XC because the supply mannequin, and a number of other “soundscapes” coming from completely different geographical areas — Sierra Nevada (S. Nevada); Powdermill Nature Reserve, Pennsylvania, USA; Hawai’i; Caples Watershed, California, USA; Sapsucker Woods, New York, USA (SSW); and Colombia — as our goal domains.
This shift from the focalized to the passive area is substantial: the recordings within the latter typically function a lot decrease signal-to-noise ratio, a number of birds vocalizing directly, and vital distractors and environmental noise, like rain or wind. As well as, completely different soundscapes originate from completely different geographical areas, inducing excessive label shifts since a really small portion of the species in XC will seem in a given location. Furthermore, as is frequent in real-world knowledge, each the supply and goal domains are considerably class imbalanced, as a result of some species are considerably extra frequent than others. As well as, we contemplate a multi-label classification drawback since there could also be a number of birds recognized inside every recording, a big departure from the usual single-label picture classification state of affairs the place SFDA is often studied.
 |
| Illustration of the “focal → soundscapes” shift. Within the focalized area, recordings are sometimes composed of a single chook vocalization within the foreground, captured with excessive signal-to-noise ratio (SNR), although there could also be different birds vocalizing within the background. Then again, soundscapes comprise recordings from omnidirectional microphones and could be composed of a number of birds vocalizing concurrently, in addition to environmental noises from bugs, rain, vehicles, planes, and so forth. |
| Audio recordsdata |
Focal area
|
Soundscape area1 |
||
| Spectogram pictures |  |
 |
| Illustration of the distribution shift from the focal area (left) to the soundscape area (proper), by way of the audio recordsdata (prime) and spectrogram pictures (backside) of a consultant recording from every dataset. Notice that within the second audio clip, the chook track could be very faint; a standard property in soundscape recordings the place chook calls aren’t on the “foreground”. Credit: Left: XC recording by Sue Riffe (CC-BY-NC license). Proper: Excerpt from a recording made obtainable by Kahl, Charif, & Klinck. (2022) “A group of fully-annotated soundscape recordings from the Northeastern United States” from the SSW soundscape dataset (CC-BY license). |
State-of-the-art SFDA fashions carry out poorly on bioacoustics shifts
As a place to begin, we benchmark six state-of-the-art SFDA strategies on our bioacoustics benchmark, and examine them to the non-adapted baseline (the supply mannequin). Our findings are stunning: with out exception, present strategies are unable to persistently outperform the supply mannequin on all goal domains. The truth is, they typically underperform it considerably.
For example, Tent, a latest technique, goals to make fashions produce assured predictions for every instance by decreasing the uncertainty of the mannequin’s output chances. Whereas Tent performs properly in varied duties, it would not work successfully for our bioacoustics job. Within the single-label state of affairs, minimizing entropy forces the mannequin to decide on a single class for every instance confidently. Nevertheless, in our multi-label state of affairs, there is no such constraint that any class needs to be chosen as being current. Mixed with vital distribution shifts, this could trigger the mannequin to break down, resulting in zero chances for all courses. Different benchmarked strategies like SHOT, AdaBN, Tent, NRC, DUST and Pseudo-Labelling, that are robust baselines for traditional SFDA benchmarks, additionally wrestle with this bioacoustics job.
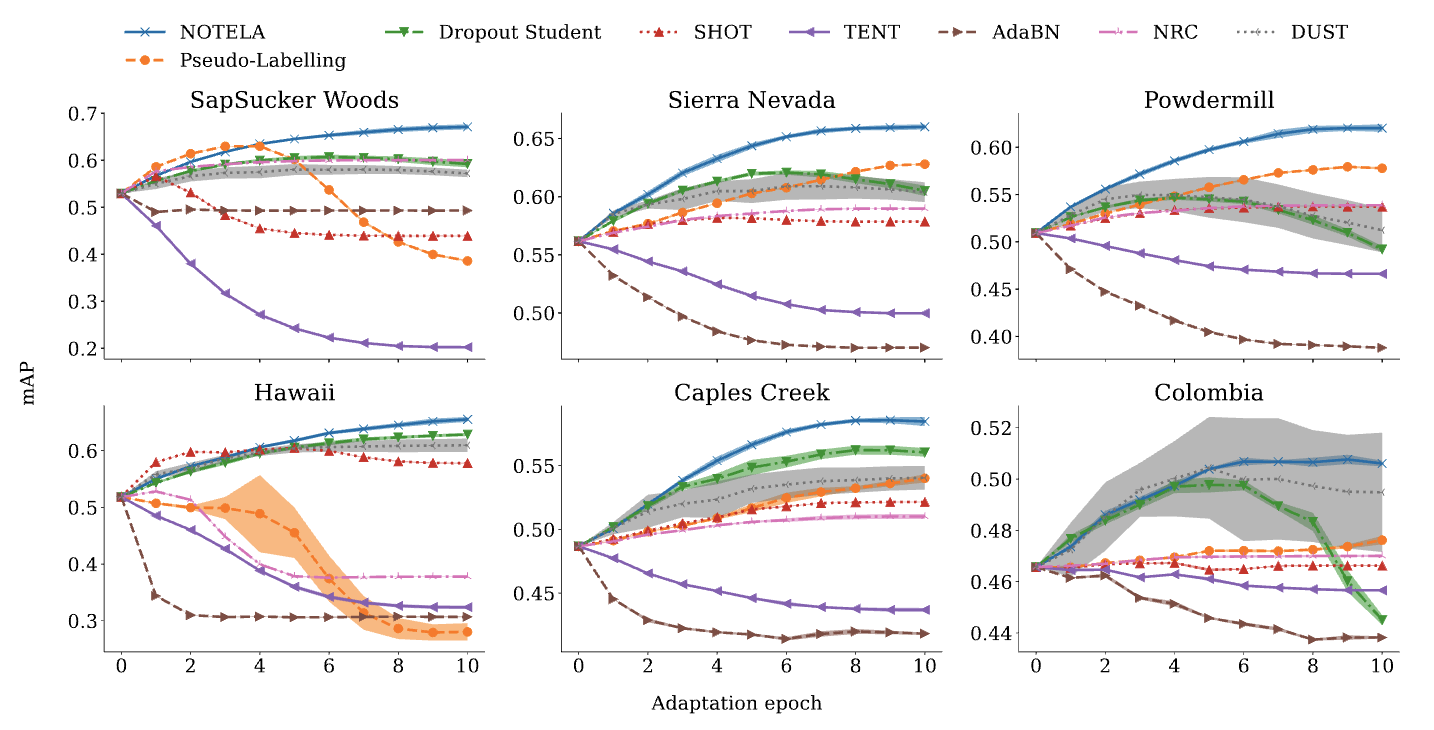 |
| Evolution of the check imply common precision (mAP), a regular metric for multilabel classification, all through the variation process on the six soundscape datasets. We benchmark our proposed NOTELA and Dropout Scholar (see under), in addition to SHOT, AdaBN, Tent, NRC, DUST and Pseudo-Labelling. Other than NOTELA, all different strategies fail to persistently enhance the supply mannequin. |
Introducing NOisy pupil TEacher with Laplacian Adjustment (NOTELA)
Nonetheless, a surprisingly constructive outcome stands out: the much less celebrated Noisy Scholar precept seems promising. This unsupervised strategy encourages the mannequin to reconstruct its personal predictions on some goal dataset, however underneath the appliance of random noise. Whereas noise could also be launched by varied channels, we attempt for simplicity and use mannequin dropout as the one noise supply: we due to this fact consult with this strategy as Dropout Scholar (DS). In a nutshell, it encourages the mannequin to restrict the affect of particular person neurons (or filters) when making predictions on a selected goal dataset.
DS, whereas efficient, faces a mannequin collapse subject on varied goal domains. We hypothesize this occurs as a result of the supply mannequin initially lacks confidence in these goal domains. We suggest enhancing DS stability through the use of the function house instantly as an auxiliary supply of fact. NOTELA does this by encouraging comparable pseudo-labels for close by factors within the function house, impressed by NRC’s technique and Laplacian regularization. This easy strategy is visualized under, and persistently and considerably outperforms the supply mannequin in each audio and visible duties.
 |
 |
| NOTELA in motion. The audio recordings are forwarded by the total mannequin to acquire a primary set of predictions, that are then refined by Laplacian regularization, a type of post-processing primarily based on clustering close by factors. Lastly, the refined predictions are used as targets for the noisy mannequin to reconstruct. |
Conclusion
The usual synthetic picture classification benchmarks have inadvertently restricted our understanding of the true generalizability and robustness of SFDA strategies. We advocate for broadening the scope and undertake a brand new evaluation framework that includes naturally-occurring distribution shifts from bioacoustics. We additionally hope that NOTELA serves as a sturdy baseline to facilitate analysis in that course. NOTELA’s robust efficiency maybe factors to 2 elements that may result in creating extra generalizable fashions: first, creating strategies with an eye fixed in the direction of more durable issues and second, favoring easy modeling ideas. Nevertheless, there’s nonetheless future work to be achieved to pinpoint and comprehend present strategies’ failure modes on more durable issues. We consider that our analysis represents a big step on this course, serving as a basis for designing SFDA strategies with better generalizability.
Acknowledgements
One of many authors of this submit, Eleni Triantafillou, is now at Google DeepMind. We’re posting this weblog submit on behalf of the authors of the NOTELA paper: Malik Boudiaf, Tom Denton, Bart van Merriënboer, Vincent Dumoulin*, Eleni Triantafillou* (the place * denotes equal contribution). We thank our co-authors for the arduous work on this paper and the remainder of the Perch staff for his or her help and suggestions.
1Notice that on this audio clip, the chook track could be very faint; a standard property in soundscape recordings the place chook calls aren’t on the “foreground”. ↩