


The present research examines how properly LLMs align with fascinating attributes, similar to helpfulness, harmlessness, factual accuracy, and creativity. The first focus is on a two-stage course of that includes studying a reward mannequin from human preferences after which aligning the language mannequin to maximise this reward. It addresses two key points:
- Enhancing alignment by contemplating completely different transformations of the realized reward.
- Successfully combining a number of reward fashions when aligning language fashions to numerous attributes.
Nonetheless, the problem lies within the want for a exactly outlined purpose for alignment, which results in exploring varied transformation and aggregation strategies with out a clear guideline.
Researchers from the College of Chicago, Google Analysis, Google DeepMind, and Stanford College point out the issue of aligning language fashions to human preferences by studying a reward mannequin from desire information and updating the language mannequin, proposing a metamorphosis method for rewards and the mixture of a number of reward fashions. The derived transformation emphasizes bettering poorly performing outputs and permits principled aggregation of rewards, resulting in substantial enhancements in aligning language fashions to be useful and innocent.

Numerous methods deal with reward hacking in Reinforcement Studying from Human Suggestions (RLHF), together with reward mannequin averaging, constrained optimization, and iterative human desire assortment. By proposing a complementary technique, the research explores aligning language fashions to a number of aims, with frequent approaches involving weighted sum mixtures of particular person reward fashions. The transformation method introduced applies to alignment methods maximizing anticipated utility. Whereas some alignment strategies use desire labels immediately, rankings are computed from an combination when aligning to a number of properties. It addresses the necessity for a bounded utility perform.
The analysis mentions a metamorphosis method for aligning language fashions to human preferences by studying a reward mannequin from desire information and updating the language mannequin. The researchers use a probabilistic interpretation of the alignment process to establish a pure selection for transformation for rewards realized from Bradley-Terry desire fashions. The derived transformation emphasizes bettering poorly performing outputs and mitigates underfitting and reward hacking. The research additionally explores the mixture of a number of reward fashions and permits principled aggregation of rewards by linking summation to logical conjunction. Experiments are carried out, aligning language fashions to be useful and innocent utilizing RLHF and displaying substantial enhancements over the baseline method.
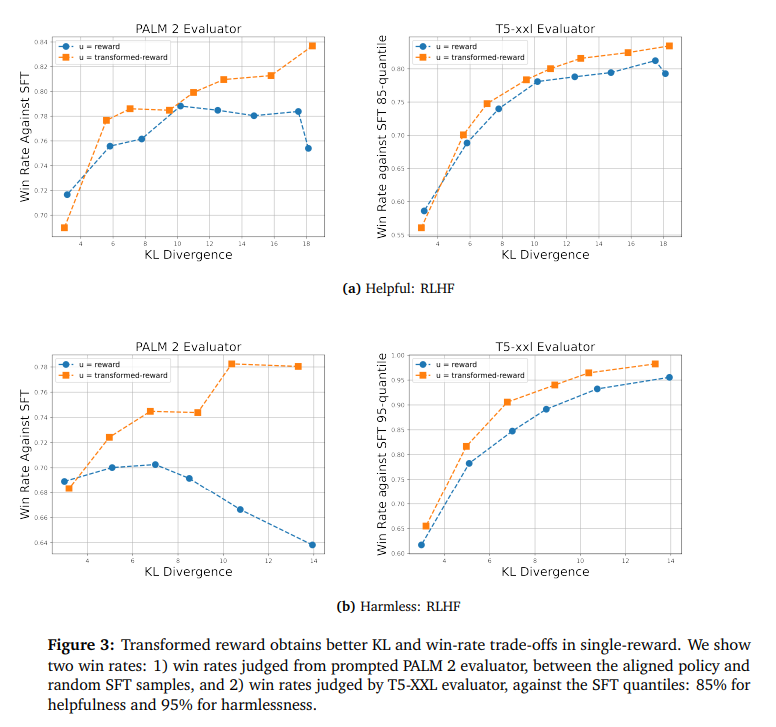
In comparison with the baseline method, the method demonstrates substantial enhancements in aligning language fashions to be useful and innocent utilizing RLHF. The transformation method for rewards and mixing a number of reward fashions present promising ends in aligning language fashions to human preferences. Summing the remodeled rewards corresponds higher to logical AND, resulting in extra balanced reward distributions and outperforming the baseline reward technique. The transformed-aligned mannequin outperforms the baseline in best-of-k and low-KL circumstances, whereas in high-KL circumstances, the transformed-reward dramatically outperforms the raw-reward baseline. The experiments carried out within the research present proof of the effectiveness of the talked about strategies in bettering the alignment of language fashions to human preferences.
In conclusion, The analysis proposes a method for aligning language fashions to human preferences, specializing in bettering poorly performing outputs and enabling principled aggregation of rewards. The transformation for rewards realized from Bradley-Terry desire fashions has two important properties: it improves poorly performing outputs and permits for principled reward aggregation. Experiments carried out utilizing RLHF reveal substantial enhancements over the baseline method, proving the effectiveness of the proposed strategies. It emphasizes the significance of contemplating each helpfulness and harmlessness in aligning language fashions, and the developed strategies present a promising method to attaining this alignment by combining a number of reward fashions and utilizing logical conjunction in reward aggregation.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.