


The transformer structure has improved pure language processing, with current developments achieved by way of scaling efforts from hundreds of thousands to billion-parameter fashions. Nevertheless, bigger fashions’ elevated computational value and reminiscence footprint restrict their practicality, benefiting only some main companies. Extending coaching period necessitates bigger datasets, which is difficult as even intensive datasets turn out to be inadequate. Observations point out diminishing returns with elevated mannequin depth, mirroring challenges in deep convolutional neural networks for laptop imaginative and prescient. Options like DenseNets, facilitating direct entry to earlier layer outputs, have emerged to deal with this concern, reflecting parallels between NLP and laptop imaginative and prescient developments.
EPFL and the College of Geneva researchers developed DenseFormer, a modification to plain transformer structure that enhances mannequin perplexity with out dimension enhance. By incorporating Depth-Weighted-Common (DWA) steps after every transformer block, DenseFormer achieves coherent data movement patterns, enhancing information effectivity. Like DenseNets, DenseFormer employs weighted averages of previous block outputs as inputs for subsequent blocks, enhancing mannequin compactness, pace, and reminiscence effectivity throughout inference. DenseFormers outperform deeper transformers in numerous settings, providing higher speed-performance trade-offs with out requiring extra information. Moreover, insights from realized DWA weights point out enhanced reusability of early options, reinforcing DenseFormer’s effectiveness in language modeling.
Current analysis highlights diminishing returns with deeper fashions in each language and imaginative and prescient duties. Strategies like residual connections and DenseNets alleviate this by enhancing data movement between layers. DenseFormer, impressed by DenseNets, permits direct entry to previous representations in transformer blocks, enhancing effectivity with out growing dimension. Though comparable concepts like Depthwise Consideration and interleaving previous representations exist, DenseFormer’s realized weighted averaging presents superior efficiency. Whereas conventional transformer variations deal with inside adjustments, DenseFormer operates between blocks, making it appropriate with present proposals. Moreover, issues for {hardware} effectivity guarantee negligible overhead. A number of mannequin approaches, like mixtures of consultants, additionally profit from DenseFormer’s adaptability, which emphasizes communication between fashions.
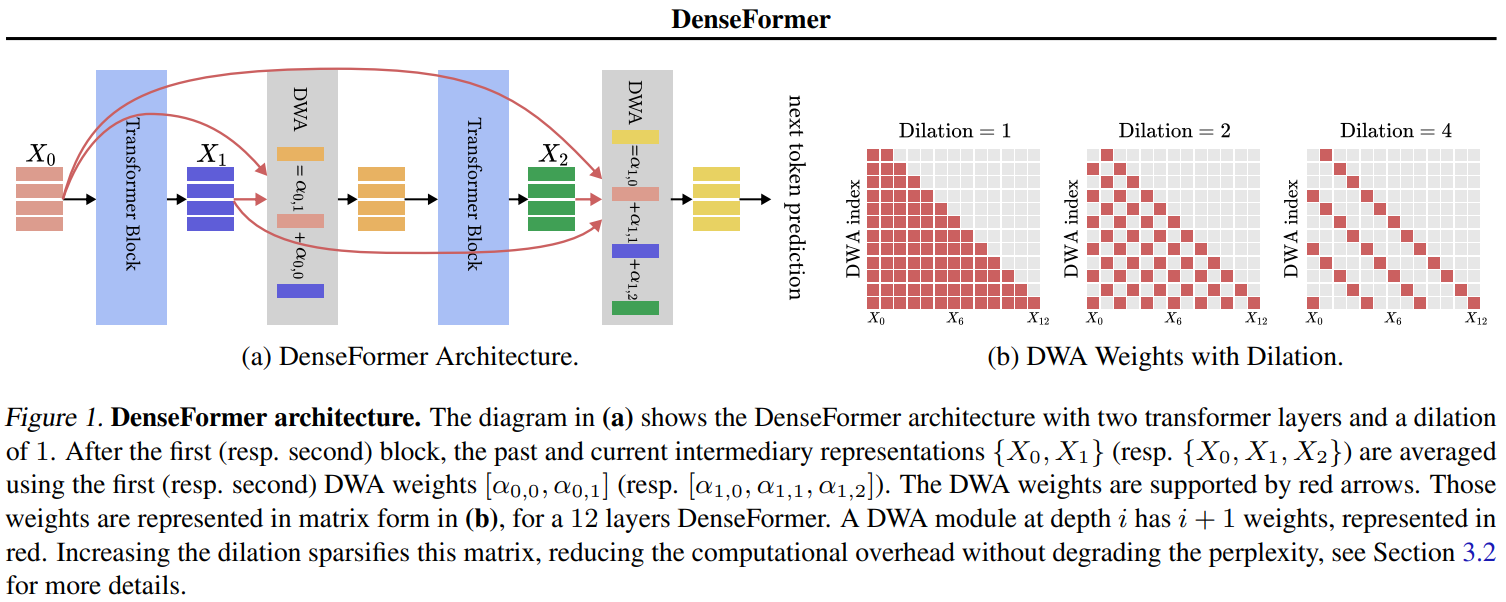
DenseFormer enhances the usual Transformer structure by incorporating DWA modules after every transformer block. These modules allow weighted averages between the present block’s output, outputs from earlier blocks, and the preliminary embedded enter. Initializing with DWA modules performing as identification capabilities, the mannequin retains compatibility with normal Transformers. Researchers observe negligible will increase in mannequin dimension and reminiscence overhead. To additional cut back computational prices, researchers introduce Dilated DenseFormer, which specifies DWA weights by periodically setting them to zero. Moreover, the research explores Periodic DenseFormer, various the frequency of DWA module addition, resulting in important computational financial savings with out noticeable efficiency degradation.

Within the experiments evaluating DenseFormer’s efficiency in language modeling duties, researchers evaluate it in opposition to normal Transformer architectures throughout numerous metrics like mannequin dimension, inference time, coaching time, and perplexity. Baselines embrace architectures of comparable depth, inference time, perplexity, and coaching time. DenseFormer persistently outperforms same-depth baselines, attaining superior perplexity with smaller fashions. It additionally matches or outperforms deeper fashions in perplexity whereas being quicker at inference. Furthermore, experiments with dilation and DWA interval variations reveal their affect on effectivity, with a dilation of 4 and a DWA interval of 5 yielding the very best stability between pace and perplexity. These outcomes maintain throughout completely different datasets and sequence lengths.
In conclusion, DenseFormer enhances the usual transformer structure with a DWA module after every block to entry earlier block outputs straight. Intensive experimentation demonstrated DenseFormer’s superiority in attaining a good trade-off between perplexity and pace in comparison with transformer baselines. The research additionally explored strategies like dilation and DWA periodicity to boost pace with out compromising efficiency. Future analysis will optimize DenseFormer’s implementation, examine environment friendly sparsity patterns, and develop scalable, distributed coaching strategies. DenseFormer presents a promising avenue for enhancing effectivity in pure language processing duties.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 39k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.