



Textual content-to-image diffusion fashions have proven distinctive capabilities in producing high-quality photos from textual content prompts. Nonetheless, main fashions characteristic billions of parameters and are consequently costly to run, requiring highly effective desktops or servers (e.g., Steady Diffusion, DALL·E, and Imagen). Whereas latest developments in inference options on Android through MediaPipe and iOS through Core ML have been made prior to now yr, speedy (sub-second) text-to-image era on cell units has remained out of attain.
To that finish, in “MobileDiffusion: Subsecond Textual content-to-Picture Era on Cellular Units”, we introduce a novel method with the potential for speedy text-to-image era on-device. MobileDiffusion is an environment friendly latent diffusion mannequin particularly designed for cell units. We additionally undertake DiffusionGAN to attain one-step sampling throughout inference, which fine-tunes a pre-trained diffusion mannequin whereas leveraging a GAN to mannequin the denoising step. We have now examined MobileDiffusion on iOS and Android premium units, and it could possibly run in half a second to generate a 512×512 high-quality picture. Its comparably small mannequin measurement of simply 520M parameters makes it uniquely fitted to cell deployment.
 |
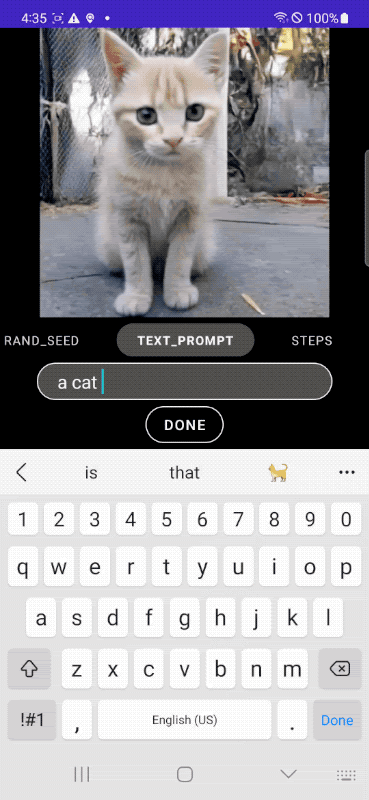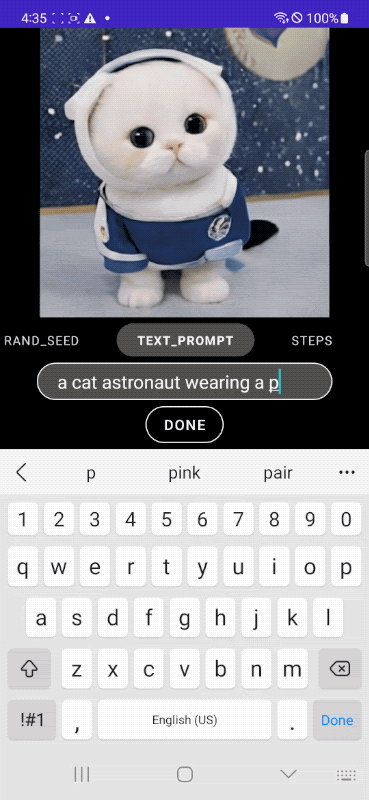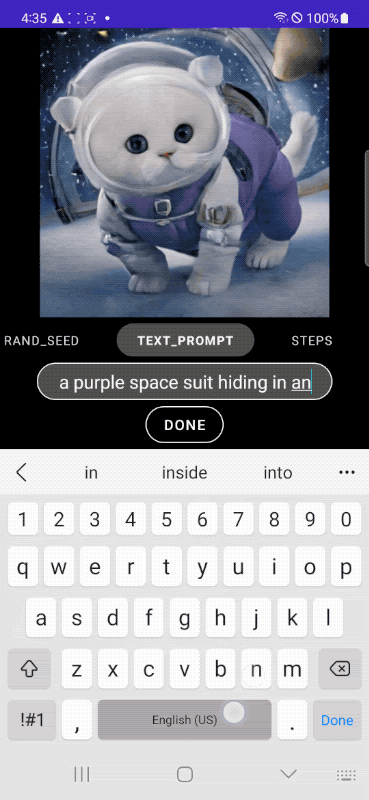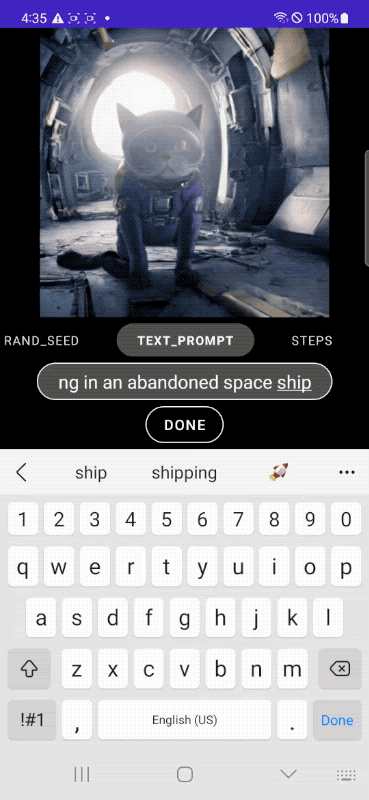 |

| Speedy text-to-image era on-device. |
Background
The relative inefficiency of text-to-image diffusion fashions arises from two major challenges. First, the inherent design of diffusion fashions requires iterative denoising to generate photos, necessitating a number of evaluations of the mannequin. Second, the complexity of the community structure in text-to-image diffusion fashions includes a considerable variety of parameters, commonly reaching into the billions and leading to computationally costly evaluations. In consequence, regardless of the potential advantages of deploying generative fashions on cell units, equivalent to enhancing consumer expertise and addressing rising privateness considerations, it stays comparatively unexplored throughout the present literature.
The optimization of inference effectivity in text-to-image diffusion fashions has been an lively analysis space. Earlier research predominantly focus on addressing the primary problem, searching for to cut back the variety of operate evaluations (NFEs). Leveraging superior numerical solvers (e.g., DPM) or distillation methods (e.g., progressive distillation, consistency distillation), the variety of essential sampling steps have considerably diminished from a number of a whole bunch to single digits. Some latest methods, like DiffusionGAN and Adversarial Diffusion Distillation, even scale back to a single essential step.
Nonetheless, on cell units, even a small variety of analysis steps could be gradual because of the complexity of mannequin structure. Up to now, the architectural effectivity of text-to-image diffusion fashions has obtained comparatively much less consideration. A handful of earlier works briefly touches upon this matter, involving the elimination of redundant neural community blocks (e.g., SnapFusion). Nonetheless, these efforts lack a complete evaluation of every part throughout the mannequin structure, thereby falling in need of offering a holistic information for designing extremely environment friendly architectures.
MobileDiffusion
Successfully overcoming the challenges imposed by the restricted computational energy of cell units requires an in-depth and holistic exploration of the mannequin’s architectural effectivity. In pursuit of this goal, our analysis undertakes an in depth examination of every constituent and computational operation inside Steady Diffusion’s UNet structure. We current a complete information for crafting extremely environment friendly text-to-image diffusion fashions culminating within the MobileDiffusion.
The design of MobileDiffusion follows that of latent diffusion fashions. It incorporates three elements: a textual content encoder, a diffusion UNet, and a picture decoder. For the textual content encoder, we use CLIP-ViT/L14, which is a small mannequin (125M parameters) appropriate for cell. We then flip our focus to the diffusion UNet and picture decoder.
Diffusion UNet
As illustrated within the determine under, diffusion UNets generally interleave transformer blocks and convolution blocks. We conduct a complete investigation of those two elementary constructing blocks. All through the examine, we management the coaching pipeline (e.g., knowledge, optimizer) to check the results of various architectures.
In traditional text-to-image diffusion fashions, a transformer block consists of a self-attention layer (SA) for modeling long-range dependencies amongst visible options, a cross-attention layer (CA) to seize interactions between textual content conditioning and visible options, and a feed-forward layer (FF) to post-process the output of consideration layers. These transformer blocks maintain a pivotal function in text-to-image diffusion fashions, serving as the first elements accountable for textual content comprehension. Nonetheless, in addition they pose a major effectivity problem, given the computational expense of the eye operation, which is quadratic to the sequence size. We observe the thought of UViT structure, which locations extra transformer blocks on the bottleneck of the UNet. This design selection is motivated by the truth that the eye computation is much less resource-intensive on the bottleneck as a consequence of its decrease dimensionality.
 |
| Our UNet structure incorporates extra transformers within the center, and skips self-attention (SA) layers at increased resolutions. |

Convolution blocks, particularly ResNet blocks, are deployed at every degree of the UNet. Whereas these blocks are instrumental for characteristic extraction and data movement, the related computational prices, particularly at high-resolution ranges, could be substantial. One confirmed method on this context is separable convolution. We noticed that changing common convolution layers with light-weight separable convolution layers within the deeper segments of the UNet yields related efficiency.
Within the determine under, we evaluate the UNets of a number of diffusion fashions. Our MobileDiffusion reveals superior effectivity by way of FLOPs (floating-point operations) and variety of parameters.
 |
| Comparability of some diffusion UNets. |

Picture decoder
Along with the UNet, we additionally optimized the picture decoder. We skilled a variational autoencoder (VAE) to encode an RGB picture to an 8-channel latent variable, with 8× smaller spatial measurement of the picture. A latent variable could be decoded to a picture and will get 8× bigger in measurement. To additional improve effectivity, we design a light-weight decoder structure by pruning the unique’s width and depth. The ensuing light-weight decoder results in a major efficiency enhance, with almost 50% latency enchancment and higher high quality. For extra particulars, please check with our paper.
 |
| VAE reconstruction. Our VAE decoders have higher visible high quality than SD (Steady Diffusion). |

| Decoder | #Params (M) | PSNR↑ | SSIM↑ | LPIPS↓ |
| SD | 49.5 | 26.7 | 0.76 | 0.037 |
| Ours | 39.3 | 30.0 | 0.83 | 0.032 |
| Ours-Lite | 9.8 | 30.2 | 0.84 | 0.032 |
One-step sampling
Along with optimizing the mannequin structure, we undertake a DiffusionGAN hybrid to attain one-step sampling. Coaching DiffusionGAN hybrid fashions for text-to-image era encounters a number of intricacies. Notably, the discriminator, a classifier distinguishing actual knowledge and generated knowledge, should make judgments based mostly on each texture and semantics. Furthermore, the price of coaching text-to-image fashions could be extraordinarily excessive, notably within the case of GAN-based fashions, the place the discriminator introduces extra parameters. Purely GAN-based text-to-image fashions (e.g., StyleGAN-T, GigaGAN) confront related complexities, leading to extremely intricate and costly coaching.
To beat these challenges, we use a pre-trained diffusion UNet to initialize the generator and discriminator. This design permits seamless initialization with the pre-trained diffusion mannequin. We postulate that the inner options throughout the diffusion mannequin comprise wealthy info of the intricate interaction between textual and visible knowledge. This initialization technique considerably streamlines the coaching.
The determine under illustrates the coaching process. After initialization, a loud picture is shipped to the generator for one-step diffusion. The result’s evaluated towards floor fact with a reconstruction loss, just like diffusion mannequin coaching. We then add noise to the output and ship it to the discriminator, whose result’s evaluated with a GAN loss, successfully adopting the GAN to mannequin a denoising step. Through the use of pre-trained weights to initialize the generator and the discriminator, the coaching turns into a fine-tuning course of, which converges in lower than 10K iterations.
 |
| Illustration of DiffusionGAN fine-tuning. |

Outcomes
Beneath we present instance photos generated by our MobileDiffusion with DiffusionGAN one-step sampling. With such a compact mannequin (520M parameters in complete), MobileDiffusion can generate high-quality numerous photos for numerous domains.
 |
| Pictures generated by our MobileDiffusion |

We measured the efficiency of our MobileDiffusion on each iOS and Android units, utilizing totally different runtime optimizers. The latency numbers are reported under. We see that MobileDiffusion may be very environment friendly and may run inside half a second to generate a 512×512 picture. This lightning pace doubtlessly permits many fascinating use instances on cell units.
 |
| Latency measurements (s) on cell units. |

Conclusion
With superior effectivity by way of latency and measurement, MobileDiffusion has the potential to be a really pleasant choice for cell deployments given its functionality to allow a speedy picture era expertise whereas typing textual content prompts. And we are going to guarantee any software of this know-how might be in-line with Google’s accountable AI practices.
Acknowledgments
We wish to thank our collaborators and contributors that helped deliver MobileDiffusion to on-device: Zhisheng Xiao, Yanwu Xu, Jiuqiang Tang, Haolin Jia, Lutz Justen, Daniel Fenner, Ronald Wotzlaw, Jianing Wei, Raman Sarokin, Juhyun Lee, Andrei Kulik, Chuo-Ling Chang, and Matthias Grundmann.