


Massive Language Fashions (LLMs) have demonstrated outstanding versatility in dealing with numerous language-centric functions. To increase their capabilities to multimodal inputs, Multimodal Massive Language Fashions (MLLMs) have gained vital consideration. These fashions are essential for creating versatile, general-purpose assistants that may perceive data from various modalities, together with textual content, photographs, movies, and audio.
Modern MLLMs, equivalent to LLaVA, usually comply with a two-stage coaching protocol: (1) Imaginative and prescient-Language Alignment, the place a static projector is skilled to synchronize visible options with the language mannequin’s phrase embedding area, enabling the LLM to know visible content material; and (2) Multimodal Instruction Tuning, the place the LLM is fine-tuned on multimodal instruction knowledge to reinforce its capacity to reply to diversified consumer requests involving visible content material.
Regardless of the vital significance of those two phases, the projector’s construction and LLM tuning technique have been comparatively underexplored. Most present analysis focuses on scaling up pretraining knowledge, instruction-following knowledge, visible encoders, or language fashions. Nevertheless, the realized mannequin with static parameters might restrict the potential for dealing with various multimodal duties.
To handle this limitation, researchers have proposed HyperLLaVA, a dynamic model of LLaVA that advantages from a rigorously designed knowledgeable module derived from HyperNetworks, as illustrated in Determine 2. This knowledgeable module generates dynamic parameters primarily based on the enter data, enabling the mannequin to adaptively tune each the projector and LLM layers for enhanced reasoning talents throughout various multimodal duties.
HyperLLaVA is skilled in two steps:
- In vision-language alignment, the projector is split into static layers (the unique MLP in LLaVA) and dynamic layers (visible knowledgeable). The static layers’ parameters are mounted, whereas the dynamic layers’ parameters are dynamically generated primarily based on visible enter. The visible knowledgeable, leveraging HyperNetworks, assists the static projector in studying a visual-specific projector that adaptively fashions the visible options in accordance with visible steerage. This method permits the projector to ship adaptive visible tokens to the language semantic area.
- Within the multimodal instruction tuning stage, the LLM is provided with a language knowledgeable, which fashions dynamic parameters for LLM blocks. The intermediate output of the LLM is considered language steerage that guides the language knowledgeable in offering an improved instruction-specific comprehension of the consumer’s request. By producing distinctive parameters for each enter, the MLLM will increase its flexibility, permitting it to utilize similarities between samples throughout datasets and keep away from potential interference between samples inside the identical dataset.
The proposed language knowledgeable serves as a parameter-efficient fine-tuning method for MLLMs, yielding comparable efficiency to the unique LLaVA whereas enhancing the mannequin’s capacity to deal with various multimodal duties.
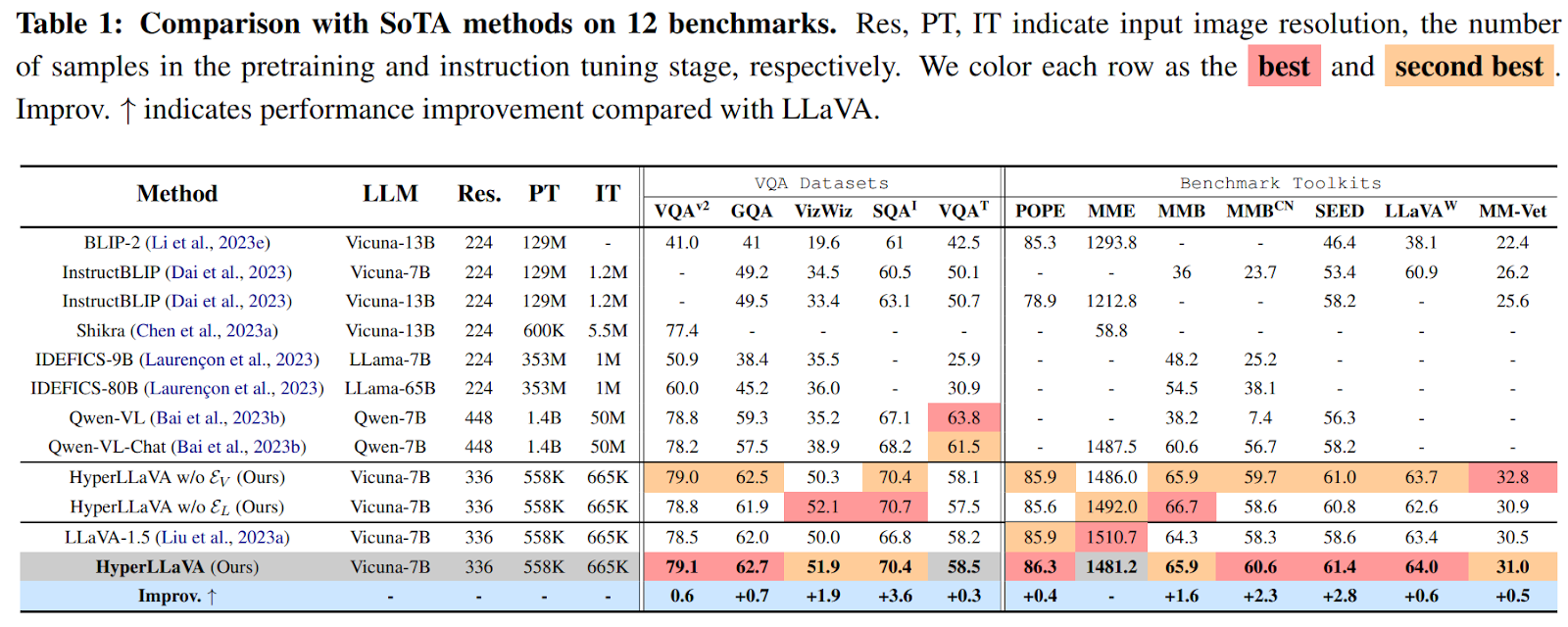
Of their experiments, the researchers evaluated HyperLLaVA on a number of datasets, together with 5 VQA datasets (VQAv2, GQA, VizWiz, SQAI, and VQAT) and 7 Benchmark Toolkits (POPE, MME, MMB, MMBCN, SEED, LLaVAW, and MM-Vet). The outcomes proven in Desk 1 exhibit that HyperLLaVA outperforms present state-of-the-art approaches, together with bigger MLLMs with billions of trainable parameters, on virtually all multimodal situations throughout these benchmarks. The rigorously designed light-weight visible and language specialists empower the static projector and LLM to facilitate completely different multimodal duties, surpassing the efficiency of the unique LLaVA throughout 11 out of 12 benchmarks.
In conclusion, HyperLLaVA’s modern, dynamic tuning technique paves the best way for developments in multimodal studying techniques. By adaptively tuning projector and LLM parameters and integrating dynamic visible and language specialists, the researchers have launched a parameter-efficient methodology that surpasses present efficiency benchmarks. This method gives a brand new horizon for enhancing multimodal activity performances by means of personalised, dynamic changes, doubtlessly unlocking new avenues for understanding and integrating multimodal data extra seamlessly.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our 39k+ ML SubReddit
![]()
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s captivated with analysis and the newest developments in Deep Studying, Pc Imaginative and prescient, and associated fields.